Si una lámina ocupa una región \(\mathcal{D}\) en el plano-\(xy\)
y para el punto \((x,y)\) su densidad está dada por la función
\(\rho(x,y)\) (en unidades de masa por unidad de área), se define su masa total como
\[
m=\int_{\mathcal{D}}\rho(x,y)dA
\]
(siempre que la integral exista).
Los momentos de masa con respecto a los ejes \(x\) e \(y\) se definen como
\begin{eqnarray*}
M_x=\int_{\mathcal{D}} y\rho(x,y)dA\\
M_y=\int_{\mathcal{D}} x\rho(x,y)dA
\end{eqnarray*}
Nota: el momento con respecto al eje \(x\) tiene un integrando de la forma
\(y\rho(x,y)\) pues la idea es que estamos multiplicando la densidad
en un punto \((x,y)\) por su distancia al eje \(x\).
El centro de masa de la lámina \(\mathcal{D}\) se define como el punto \((\overline{x},\overline{y})\)
donde
\[
\overline{x}=\frac{M_y}{m}, \quad \overline{y}=\frac{M_x}{m}
\]
Encuentra el centro de masa de una lámina triangular cuyos vértices están en los
puntos \((0,0),(0,a)\) y \((a/3,2a)\), donde \(a>0\) es una constante y donde suponemos
una densidad constante.
Mismas suposiciones del inciso anterior pero ahora la densidad está dada por
la función \(\rho(x,y)=3x+5y+2\).
Encuentra el centro de masa de una lámina \(\mathcal{D}\) acotada por las
parábolas \(x=y^2, y=x^2\) si su dendisdad está dada por \(\rho(x,y)=ky\), donde
\(k>0\) es constante.
Determina la masa de una lámina acotada por el eje \(x\) y el
segmento de parábola \(y=2x-x^2\), para \(x=0,x=2\), si la densidad
está dada por \(\rho(x,y)=\frac{1-y}{1+x}\).
Teorema
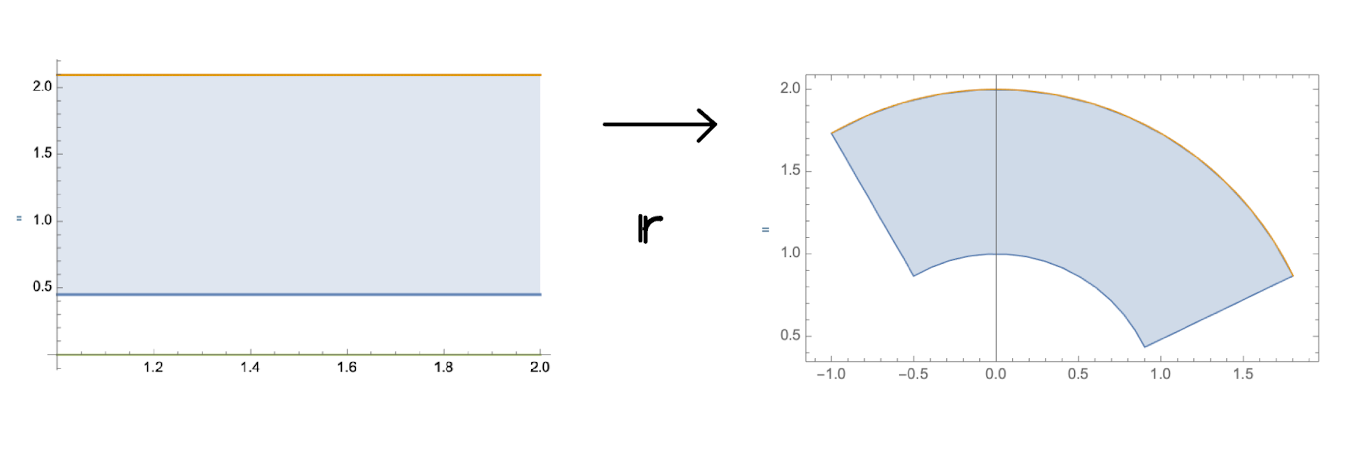
Consideramos las coordenadas polares
\[
\mathbb{r}(r,\theta)=(r\cos(\theta), r\sen(\theta))
\]
Tomemos el rectángulo \(\mathcal{R}=[a,b]\times [\theta_1,\theta_2]\),
con \( 0< a< b \), \(0\leq \theta_1 < \theta_2 < 2\pi\) y
tomemos \(\mathcal{S}=\mathbb{r}(\mathcal{R})\).
Supongamos que \(f\) es una función continua en \(\mathcal{S}\). Entonces
\[
\int_{\mathcal{S}}f(x,y)dx\otimes dy= \int_{a}^b \int_{\theta_1}^{\theta_2}f(r\cos(\theta),r\sen(\theta))rdr\otimes d\theta
\]
Ejercicio
Una lámina tiene la forma de la intersección de las circunferencias
\(x^2+y^2=1, x^2+y^2=2y\). Calcula su centro de masa si la
densidad de un punto es proporcional al inverso de la distancia del punto al origen.
Ejercicio
Encuentra el volumen del sólido que está por debado del paraboloide elíptico
\(z=x^2+2y^2\), arriba del plano \(xy\) y adentro del cilindro \(x^2+y^2=2x\).
Ejercicio
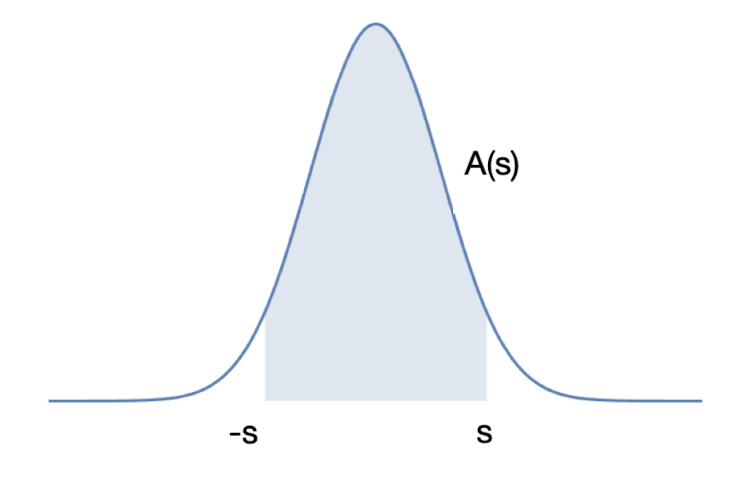
Para \(s>0\) denota
\[
A(s)=\int_{-s}^s e^{-u^2}du
\]
Prueba que
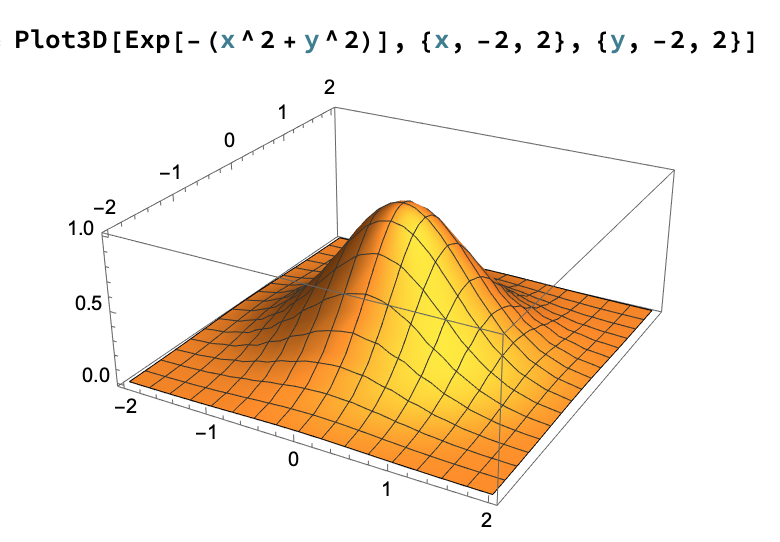
\[
(A(s))^2=\int_{\mathcal{R}}e^{-(x^2+y^2)}dx\otimes dy
\]
donde \(\mathcal{R}=[-s,s]\times [-s,s]\).
Si \(C_1\) y \(C_2\) son discos de tal forma que
\(C_1 \subset \mathcal{R}\subset C_2\). Prueba que
\[
\int_{C_1} e^{-(x^2+y^2)} \leq (A(s))^2 \leq \int_{C_2} e^{-(x^2+y^2)}
\]
Usa un cambio de variable en coordenadas polares y usa
las desigualdades anteriores para probar
\[
\lim_{s\to \infty} A(s)=\sqrt{\pi}
\]
Esto prueba que \(\int_{-\infty}^\infty e^{-u^2}du = \sqrt{\pi}\).
Aplicando directamente el Teorema de Fubini resulta
\[
\int_{\mathcal{R}}e^{-(x^2+y^2)}dx\otimes dy = \int_{-s}^{s}\left( \int_{-s}^s e^{-(x^2+y^2)}dx\right)dy
\]
y por las propiedades de la exponencial \(e^{-(x^2+y^2)}=e^{-x^2}e^{-y^2}\), así que haciendo las
integrales interadas obtenemos
\begin{eqnarray*}
\int_{-s}^{s}\left( \int_{-s}^s e^{-(x^2+y^2)}dx\right)dy&=& \int_{-s}^s \left( \int_{-s}^se^{-x^2}e^{-y^2} dx\right)dy \\
&=& \int_{-s}^s \left( e^{-y^2}\int_{-s}^se^{-x^2} dx\right)dy \\
&=& \int_{-s}^s e^{-y^2}A(s)dy
\end{eqnarray*}
donde en la última identidad usamos la definición de \(A(s)\). Notamos que \(A(s)\) es constante con respecto a
\(y\) por lo tanto podemos sacarla de la última integral y usando de nuevo la definición de \(A(s)\) obtenemos
\begin{eqnarray*}
\int_{-s}^{s}\left( \int_{-s}^s e^{-(x^2+y^2)}dx\right)dy&=&A(s)\int_{-s}^{s}e^{-y^2}dy \\
&=& A(s)^2
\end{eqnarray*}
Definamos las funciones \(f,g,h: C_2 \to \mathbb{R}\) por
\begin{eqnarray*}
f(x,y)&=&\left\{
\begin{array}{cc}
e^{-(x^2+y^2)} & (x,y)\in C_1 \\
0 & \textrm{otro caso }
\end{array}
\right.
\\
g(x,y)&=&\left\{
\begin{array}{cc}
e^{-(x^2+y^2)} & (x,y)\in \mathcal{R} \\
0 & \textrm{otro caso }
\end{array}
\right.
\\
h(x,y)&=&e^{-(x^2+y^2)}
\end{eqnarray*}
Entonces se tiene que \(f \leq g \leq h\) y por Monotonía de la integral
\[
\int_{C_2} f \leq \int_{C_2} g \leq \int_{C_2} h
\]
de lo cual se sigue que
\[
\int_{C_1}e^{-(x^2+y^2)} \leq \int_{\mathcal{R}} e^{-(x^2+y^2)} \leq \int_{C_2}e^{-(x^2+y^2)}
\]
y por el inciso anterior concluimos
\[
\int_{C_1}e^{-(x^2+y^2)} \leq A(s)^2 \leq \int_{C_2}e^{-(x^2+y^2)}
\]
Primero notamos que el radio de \(C_1\) es \(s\) y el radio de \(C_2\) es \(\sqrt{2}s\). Ahora,
usando el Teorema de cambio de variable en coordenadas polares llegamos a
\begin{eqnarray*}
\int_{C_1}e^{-(x^2+y^2)}&=& \int_{0}^{2\pi}\int_{0}^{s} e^{-r^2}r drd\theta \\
&=& \left( \int_{0}^{2\pi} 1 d\theta \right)\left( \int_{0}^s e^{-r^2}rdr\right) \\
&=& 2\pi \int_{0}^{s}e^{-r^2}rdr \\
&=& \pi\int_0^{s^2} e^{-u}du
\end{eqnarray*}
donde en la última identidad usamos el cambio de variable \(u=r^2\). Calculando la última integral obtenemos
\(\int_0^{s^2} e^{-u}du= -e^{-s^2}+e^0=1-e^{-s^2}\) y por lo tanto
\[
\int_{C_1}e^{-(x^2+y^2)}=\pi(1-e^{-s^2})
\]
De manera similar
\[
\int_{C_2}e^{-(x^2+y^2)}=\pi(1-e^{-(\sqrt{2}s)^2})
\]
Finalmente del inciso anterior
\[
\pi(1-e^{-s^2}) \leq A(s)^2 \leq \pi(1-e^{-(\sqrt{2}s)^2})
\]
por lo que al tomar límite cuando \(s\to \infty\) y usar la ley del sandwich concluimos
\[
\lim_{s\to \infty}A(s)^2=\pi \Rightarrow \lim_{s\to \infty} A(s)=\sqrt{\pi}
\]
Ejercicio
Usa un cambio de variable y el ejercicio anterior para probar que
para \(\mu,\sigma\) constantes:
\[
\frac{1}{\sigma\sqrt{2\pi}}\int_{-\infty}^{\infty} e^{-(t-\mu)^2/(2\sigma^2)}dt=1
\]
Para \(s >0\) consideramos la integral
\[
\int_{-s}^s e^{-(t-\mu)^2/(2\sigma^2)}dt
\]
y el cambio de variable \(u=(t-\mu)/(\sqrt{2}\sigma)\) para obtener
\[
\int_{-s}^s e^{-(t-\mu)^2/(2\sigma^2)}dt= \sqrt{2}\sigma \int_{-(s-\mu)/(\sqrt{2}\sigma)}^{(s-\mu)/(\sqrt{2}\sigma)}e^{-u^2}du
\]
tomando límite cuando \(s\to \infty\) y usando el ejercicio anterior llegamos a
\begin{eqnarray*}
\lim_{s\to \infty}\int_{-s}^s e^{-(t-\mu)^2/(2\sigma^2)}dt&=&\sqrt{2}\sigma \lim_{s\to \infty} \int_{-(s-\mu)/(\sqrt{2}\sigma)}^{(s-\mu)/(\sqrt{2}\sigma)}e^{-u^2}du \\
&=& \sqrt{2}\sigma \sqrt{\pi}\\
\Rightarrow \frac{1}{\sigma \sqrt{2\pi}}\int_{-\infty}^{\infty} e^{-(t-\mu)^2/(2\sigma^2)} &=&1
\end{eqnarray*}
Definición
Una variable aleatoria es una función que trata de modelar las posibilidades de un evento
(que una maquina falle, que el precio de una acción suba/baje). Lo importante de las
variables aleatorias es que queremos calcular probabilidades de eventos. Si \(X\)
es una variable aleatoria que toma valores reales queremos calcular probabilidades
de eventos como \(a\leq X \leq b\), lo cual se denota
\[
\mathbb{P}(a\leq X \leq b)
\]
Nota: la probabilidad siempre es un número en \([0,1]\) donde la idea es que un evento con
probabilidad cerca de \(0\) es poco probable y uno cerca de 1 es más probable.
Una variable aleatoria \(X\), que toma valores reales, se dice que tiene función de densidad de probabilidad
si existe una función \(f\) que satisface
\(f\geq 0\)
\(\int_{-\infty}^\infty f(t)dt=1\)
Nota: se entiende
\[
\int_{-\infty}^\infty f(t)dt=\lim_{n \to \infty}\int_{-n}^{n}f(t)dt
\]
suponiendo que para todo natural \(n\), \(\int_{-n}^nf(t)dt\) existe.
\(\mathbb{P}(a\leq X \leq b)\) se calcula como
\[
\mathbb{P}(a\leq X \leq b)=\int_a^b f(t)dt
\]
Ejercicio
Considera la función
\begin{eqnarray*}
f(t)=\left\{
\begin{array}{cc}
\mu^{-1}e^{-t/\mu} & t \geq 0 \\
0 & t < 0
\end{array}
\right.
\end{eqnarray*}
donde \(\mu > 0\) es una constante.
Prueba que \(\int_{-\infty}^{\infty}f(t)dt=1\).
Dicho tipo de función se llama
una función de densidad tipo exponencial.
Definición
Cuando se tienen dos variables aleatorias \(X,Y\), su función de densidad de probabilidad
conjunta es una función \(f:\mathbb{R}^2 \to \mathbb{R}\) que satisface:
Para una región \(\mathcal{D}\subseteq \mathbb{R}^2\) se satisface
\[
\mathbb{P}((X,Y)\in \mathcal{D})=\int_{\mathcal{D}} f(x,y)dx\otimes dy
\]
La integral anterior se puede probar que satisface
\begin{eqnarray*}
\int_{\mathbb{R}^2}f(x,y)dx\otimes dy &=&\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}f(x,y)dydx \\
&=&\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}f(x,y)dxdy \\
\end{eqnarray*}
Ejercicio
Fija dos números positivos \(a,b\). Encuentra la constante \(C>0\) para la
cual la función
\begin{eqnarray*}
f(x,y)=\left\{
\begin{array}{cc}
C xy & 0\leq x \leq a, 0\leq y \leq b \\
0 & \textrm{en otro caso}
\end{array}
\right.
\end{eqnarray*}
satisface \(\int_{\mathbb{R}^2}f=1\).
Supon que \(X,Y\) son variables aleatorias y que la función del inciso anterior
es la función de densidad conjunta de \(X,Y\). Calcula
\[
\mathbb{P}(X\geq a/2), \mathbb{P}(X\leq a/2, Y\geq b/2), \mathbb{P}(bX+aY\leq ab/2)
\]
Definición
Dos variables aleatorias, \(X,Y\), se llaman independientes si
\[
\mathbb{P}( a\leq X \leq b \quad \textrm{y} \quad c \leq Y \leq d)=
\mathbb{P}(a \leq X\leq b)\mathbb{P}(c \leq Y\leq d)
\]
para todos \(a< b, c< d\).
Si las variables aleatorias \(X\) y \(Y\) tienen funciones de densidad de probabilidad
\(f_X, f_Y\) respectivamente y si son independientes se puede probar que
su función de densidad conjunta, \(f(x,y)\), es
\[
f(x,y)=f_X(x)f_Y(y)
\]
Es decir, para toda región \(\mathcal{D}\subseteq \mathbb{R}^2\):
\[
\mathbb{P}((X,Y)\in \mathcal{D})=\int_{\mathcal{D}}f_X(x)f_Y(y)dx\otimes dy.
\]
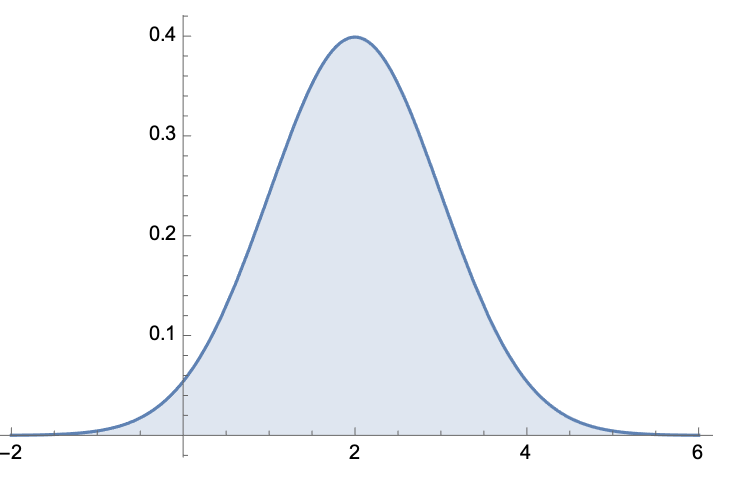
Ejercicio
Una variable aleatoria se se dice que tiene una densidad normal, con media
\(\mu\) y varianza \(\sigma\) ( o que se distribuye de manera normal) si
admite una función de densidad de probabilidad de la forma
\[
f(t)=\frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{(t-\mu)^2}{2\sigma^2}}
\]
Nota: el factor \(1/(\sigma \sqrt{2\pi})\) es para que \(\int_{-\infty}^{\infty}f(t)dt=1\).
Las funciones del tipo anterior son las que se conocen como campanas de Gauss.
Ejercicio
Supon que \(X,Y\) son variables aleatorias independientes. \(X\) tiene una función
de densidad normal con media \(\mu=45\) y varianza \(\sigma=0.5\),
\(Y\) tiene una densidad normal con media \(\mu=25\) y varianza \(\sigma=0.3\). Calcula
\(\mathbb{P}(30\leq X \leq 50, 20\leq Y \leq 30)\)
Ejercicio
Tiempos de espera se pueden modelar con variables aleatorias con función de probabilidad
de densidad de la forma
\begin{eqnarray*}
f(t)=\left\{
\begin{array}{cc}
\mu^{-1}e^{-t/\mu} & t \geq 0 \\
0 & t < 0
\end{array}
\right.
\end{eqnarray*}
donde \(\mu > 0\) es una constante (dicho tipo de función se llama
una función de densidad tipo exponencial).
Asume que el tiempo de vida de cierto tipo de focos se pude
modelar con una variable aleatoria con densidad tipo exponencial con \(\mu=1000\) (promedio
de vida del foco es 1000 horas).
Si una lámpara tiene dos focos calcula la probabilidad de que ambos focos tengan un
lapso de vida de a lo más 1000 horas.
Considera dos lámparaas cada una con un sólo foco. Calcula la probabilidad de que
alguna de ellas falle en un lapso de a lo más 1000 horas.
Considera que tienes sólo una lámpara con un sólo foco. Calcula la probabilidad de que
un foco falle, lo reemplaces y que ambos focos fallen en un lapso de a lo más 1000 horas.
Definición
Decimos que un subconjunto \(\mathcal{S} \subset \mathbb{R}^n\) es una superficie
suave parametrizada, si existe una función clase \(C^1\),
\(\mathbb{r}: \mathcal{R} \to \mathbb{R}^n\) tal que
\(\mathcal{R}\subset \mathbb{R}^2\) es una región (subconjunto compacto con interior no vacío).
\(\mathbb{r}(\mathcal{R})=\mathcal{S}\).
\(\mathcal{S}\) no se auto-corta.
Todo punto de \(\mathcal{S}\) admite un plano tangente.
A veces se da directamente la función
\(\mathbb{r}\) y decimos que un superficie parametrizada suave
es una función clase \(C^1\), \(\mathbb{r}: \mathcal{R} \to \mathbb{R}^n\) que satisface las condiciones anteriores.
Ejemplos.
No ejemplos.
Notas:
A la función \(\mathbb{r}\) se le llama una parametrización.
La condición de que la superficie no se auto-corta es
informal. La manera formal de enunciar esta condición es con topología
y dice: todo punto de la superficie adminte una vecindad que es
homeomorfa a un abierto de \(\mathbb{R}^2\).
Si la parametrización \(\mathbb{r}\) es inyectiva
entonces la condición 1 de la definición se cumple
inmediatamente. Pero a la inversa no es necesariamente cierta
como lo muestra el ejemplo de la esfera (ver más abajo).
Decimos que una función definida en un compacto con interior no vacío, \(r:\mathcal{R} \to \mathbb{R}^n\),
es clase \(C^1\) en \(\mathcal{R}\)
si existe \(V\), un abierto de \(\mathbb{R}^n\)
con \(\mathcal{R} \subset V\) y una función
\(\tilde{r}:V\to \mathbb{R}^n\), tal que
\(\tilde{r}\) restringida a \(\mathcal{R}\) coincide con \(r\).
La última condición se puede cumplir si las parciales de \(\mathbb{r}\) en todo punto de \(\mathcal{R}\) forman un
conjunto linealmente independiente. Este punto será
importante en la orientación, que se verá más adelante.
En muchos casos \(\mathcal{R}\) es un rectángulo.
Ejemplo.
Para el caso de la esfera
\(\mathcal{S}=\{(x,y,z): x^2+y^2+z^2=r^2\}\),
las coordenadas esféricas proveen la parametrización:
\begin{eqnarray*}
& & \mathbb{r}:[0,\pi]\times [0,2\pi]\to \mathbb{R}^3,\\
& & \mathbb{r}(\theta,\varphi)=(r\cos(\varphi)\sin(\theta), r\sin(\varphi)\sin(\theta), r\cos(\theta)).
\end{eqnarray*}
Es claro \(\mathcal{S}\) no se corta asi misma, que \(\mathbb{r}\) es clase \(C^1\) y utilizando coordenadas
esféricas se tiene
que \(\mathbb{r}([0,\pi]\times [0,2\pi])=\mathcal{S}\). Además el claro que todo punto tiene un plano tangente. Con
respecto a éste último punto veamos otra manera de probarlo, lo cual se generaliza a otros ejemplos de superficies.
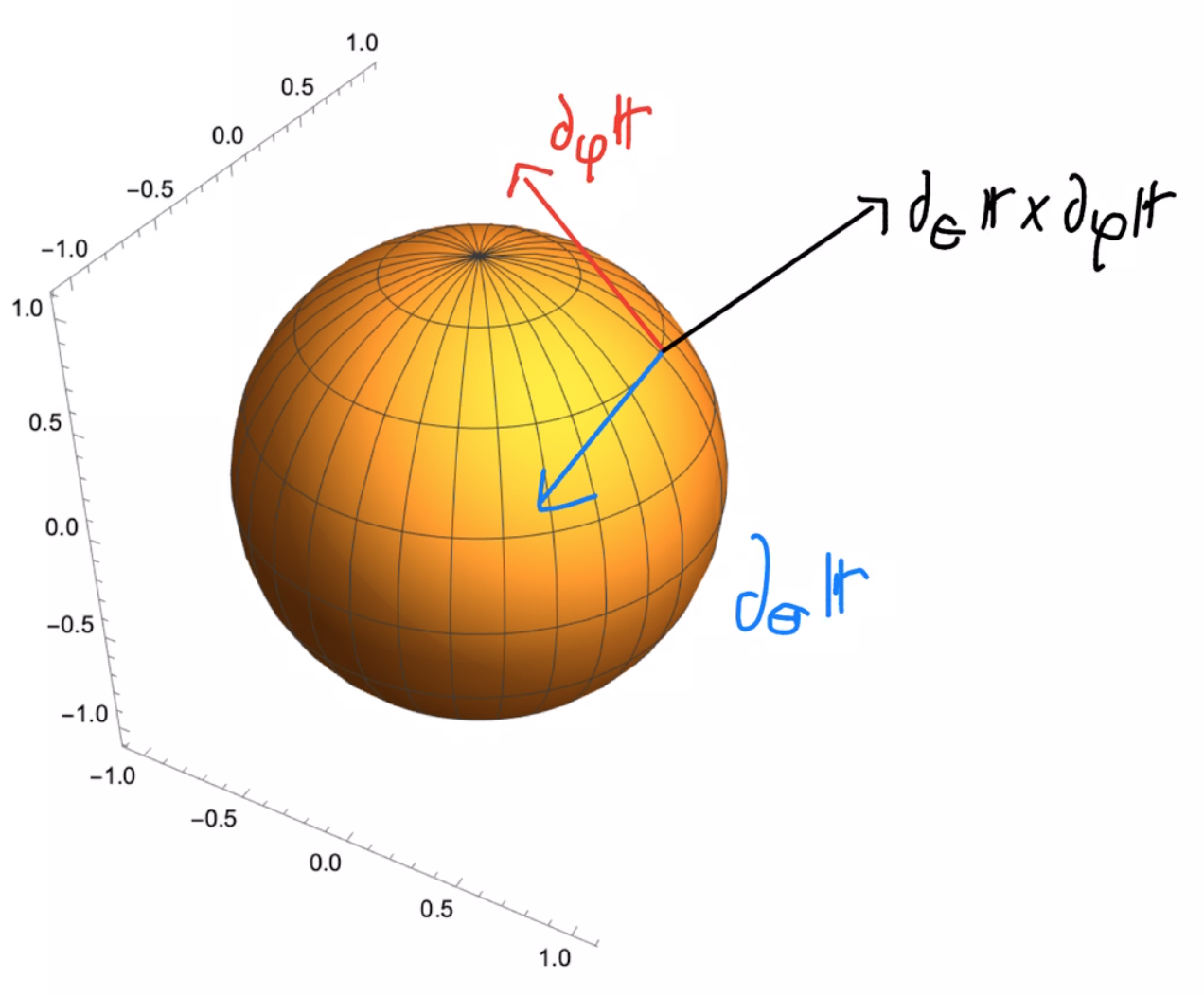
Las parciales
de \(\mathbb{r}\) en un punto cualquiera \((\theta,\varphi)\) son
\begin{eqnarray*}
\partial_\theta \mathbb{r} (\theta,\varphi)= (r\cos(\varphi)\cos(\theta), r\sin(\varphi)\cos(\theta), -r\sen(\theta)) \\
\partial_\varphi \mathbb{r} (\theta, \varphi)=(-r\sin(\varphi)\sin(\theta), r\cos(\varphi)\sin(\theta), 0)
\end{eqnarray*}
Si éstos dos dos vectores forman un conjunto linealmente
independiente entonces éstos generan al plano tangente. Para
checar que los vectores son linealmente independientes vamos usar un truco de cálculo 3: si su producto cruz
es distinto de cero entonces los vectores son linealmente independiente.
Calculando directamente el producto cruz tenemos
\[
(\partial_\theta \mathbb{r} \times \partial_\varphi \mathbb{r})(\theta,\varphi)=
\left|
\begin{array}{ccc}
\mathbb{i} & \mathbb{j} & \mathbb{k} \\
r\cos(\varphi)\cos(\theta) & r\sin(\varphi)\cos(\theta) & -r\sen(\theta) \\
-r\sin(\varphi)\sin(\theta) & r\cos(\varphi)\sin(\theta) & 0
\end{array}
\right|
=
r\sin(\theta)\mathbb{r}(\theta,\varphi)
\]
el cual siempre distinto de cero para \(\theta \ne 0, \pi\), que corresponden a los polos.
Nota: esta cuenta
NO dice que no existan planos tangentes en los polos, mas bien lo que pasa es que la pareametrización dada
no garantiza dichos planos tangentes. Sin embargo existen otras parametrizaciones para las cuales
el producto cruz es distinto de cero en los polos.
Definición
El producto fundamental de una superficie
Sea \(\mathbb{r}:\mathcal{R}\to \mathbb{R}^3\) una superficie
suave parametrizada y digamos que \(\mathbb{r}\) depende de las
variables \((u,v)\in \mathcal{R}\). El producto cruz
\[
\partial_u \mathbb{r}\times \partial_v\mathbb{r}
\]
se conoce como el producto fundamental de la superficie.
Nota.
Las derivadas parciales \(\partial_u \mathbb{r}\) y \(\partial_v\mathbb{r}\),
valuadas en un punto \((u_0,v_0)\), pueden verse como vectores tangentes a la superficie
en el punto \(\mathbb{r}(u_0,v_0)\). Si además suponemos que
\(\{\partial_u \mathbb{r}(u_0,v_0),\partial_v \mathbb{r}(u_0,v_0)\}\) es
linealmente independiente resulta que es también una base para el
plano tangente en \(\mathbb{r}(u_0,v_0)\). Pero, el producto cruz
entre dos vectores en \(\mathbb{R}^3\) es perpendicular a ambos vectores,
por lo tanto podemos pensar al producto fundamental
\(\partial_u \mathbb{r}\times \partial_v \mathbb{r}\) como un vector normal
a la superficie.
Ejercicio
Para las siguientes superficies parametrizadas calcula su producto
fundamental.
Para una parametrización
\(\mathbb{r}:\mathcal{R}\to \mathbb{R}^3\), podemos usar de nuevo
el producto fundamental para ver cómo \(\mathbb{r}\) transforma el
área de \(\mathcal{R}\).
Recordemos que, en general, la norma del producto cruz de dos vectores
\(P\) y \(Q\) es igual al área del paralelogramo generado \(P\) y \(Q\). Ahora,
fijemos \(\mathbb{r}(u_0,v_0)\) en la superficie. Ya que el plano tangente
es el mejor plano que aproxima a la superficie y tomando en cuenta de que
\(\{\partial_u \mathbb{r}(u_0,v_0),\partial_v \mathbb{r}(u_0,v_0)\}\)
forma una base para dicho espacio, tomando \(P=\partial_u \mathbb{r}(u_0,v_0)\)
y \(Q=\partial_u \mathbb{r}(u_0,v_0)\), resulta que
\[
\|\partial_u \mathbb{r}(u_0,v_0)\times \partial_v \mathbb{r}(u_0,v_0) \|
\]
de una medida de qué tanto el área de \(\mathcal{R}\) se deforma para
dar el área de la sufercie. Tomando en cuenta esto, tenemos la siguiente
definición.
Definición
Dada \(\mathcal{S}\), una superficie suave parametrizada
por \(\mathbb{r}:\mathcal{R}\to \mathbb{R}^3\), definimos su
área superficial como
\[
\textrm{Area}(\mathcal{S})=\int_{\mathcal{R}} \left\| \partial_u \mathbb{r}\times \partial_u \mathbb{r} \right\|
\]
Ejercicio
Supongamos que la superficie \(\mathcal{S}\) es la gráfica de \(f\), una
función clase \(C^1\), es decir
\[
\mathcal{S}=\{(x,y,z): (x,y)\in \mathcal{R}: z=f(x,y)\}
\]
donde \(\mathcal{R}\subset \mathbb{R}^2\) es una región y
\(f:\mathcal{R}\to \mathbb{R}\) es clase \(C^1\) en \(\mathcal{R}\).
Demuestra que el área del plano, \(z=Ax+By+C\), que está justo por arriba de la región \(\mathcal{D} \subset
\mathbb{R}^2\)
es
\[
\textrm{Area}(\mathcal{D})\sqrt{A^2+B^2+1}
\]
Ejercicio
Encuentra las áreas superficiales que se indican.
La parte del cilindro \(y^2+z^2=16\) que está sobre el plano \(xy\) y delimitada por los planos
\(x=0,x=1\).
La parte del paraboloide \(z=9-x^2-y^2\) que está por arriba
de plano \(xy\).
La parte del paraboliode \(z=2y^2-2z^2\) que está entre los cilindros
\(x^2+y^2=1, x^2+y^2=9\).
La superficie \(z=a(x^{3/2}+y^{3/2})\), \(0\leq x \leq 1, 0\leq y \leq 1\),
donde \(a>0\) es constante.
Ejercicio
Calcula el área de la superficie que se obtiene al cortar el
plano \(x+y+z=a\) con el cilindro \(x^2+y^2=a^2\), donde \(a>0\).
Calcula el área de la superficie que se obtiene al cortar la
esfera \(x^2+y^2+z^2=r^2\) con el cilindro \(x^2+y^2=rx\), donde \(r>0\).
El área de la parte de la cónica \(x^2+y^2=z^2\) que está dentro
de los planos \(z=0\), \(x+2z=3\).